ADO Dataset Iterator Action
The ADO Dataset Iterator action allows you to perform a group of actions for each row returned from a SQL query on a database using ADO.
Query
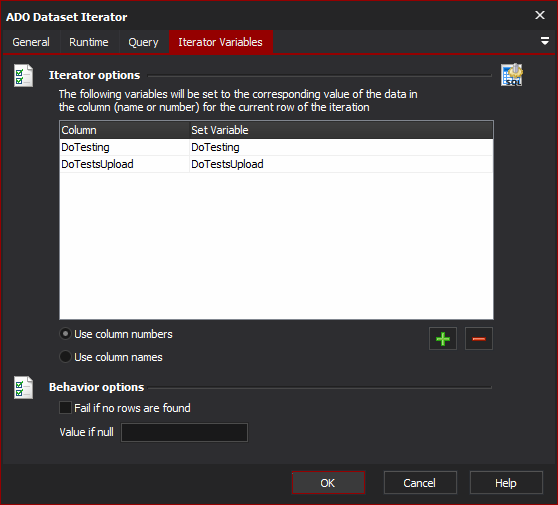
Connection String
specify a connection string to your ADO data source. You can use the built in connection string builder to create and test your connection string.
SQL
Either specify a file containing SQL, or specify the SQL statement in the text field.
SQL statement from file
The file from which to load the SQL statement to run. This file require read permissions of the user running the Automise script. The file should contain a single valid SQL statement which can be run against the database in question. Only the filename itself will have Automise expressions expanded, the text the file contains will be read as is.
Text Query
The test of an SQL statement to run. Automise expressions will be expanded on the first iteration.
Iterator Variables
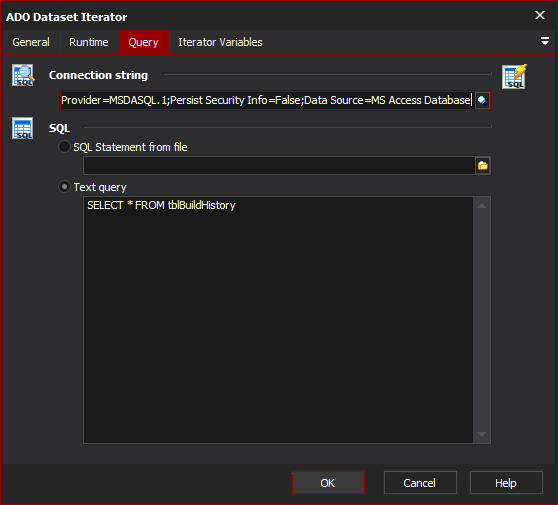
Iterator Options
Use the grid to set up which column values you want to put in variables for each iteration of the action. The above example shows that the Capability column and Version column values will be placed into the CapabilityName and VersionNum Automise variables. Use the Plus and Minus buttons to add and remove rows in the grid.
Use Column Number
Use column numbers to locate the columns listed in the variables list. This is dependent on table structure and the SQL statement. Care should be taken when database tables are altered so that the column numbers still match the columns expected.
Use Column Names
Use column names to locate the columns listed in the variables list. This makes obtaining the corrected column a little simpler and resilient to database changes. Note that this method does mean the iteration will take longer, however this is only dependent on the number columns contained in the dataset returned to the iterator.
Behaviour Options
Fail if no rows are found
The action will be failed if no rows are returned from the SQL statement provided. Helpful for detecting that there are errors in either the database or SQL statement itself. If SQL statement is expected to return zero rows on some occasions then leave this option off.
Value if null
What value should be returned to the variables if NULL is returned in the dataset. This value is global to all columns, and if specific column values are required for NULL then this should be specified in the SQL statement provided.